第 4 章 数据科学与统计学
数据科学导论是应用统计学、数据科学与大数据技术专业非常重要的一门专业必修课,力图帮助新生了解、认知专业,对涉及专业知识、专业技能,以及专业能力与素养等方面,进行比较全面的引导和指导性介绍,目的是为今后的大学和专业学习奠定最基本的基础。总而言之,本课程希望帮助刚刚进入大学,即将开始专业学习的学生:
启蒙大学,启迪专业! 跳出舒适区,摆脱迷茫,重塑自我,开启正确的大学生活和专业学习模式!
数据科学导论采用模块化教学,设定如下六个内容模块:
- [ ]课程概述
- [ ]专业介绍
- [ ]数据科学的计算机生态系统
- [x]数据科学与统计学
- [ ]数据科学的数学、统计思维
- [ ]数据科学与人工智能
构建自己的知识体系,全方位提升自己,用自己确定的能力,应对未来的不确定性!
今天介绍第四个模块,对两个专业最核心的两个概念数据科学和统计学的内涵和外延做简单介绍,对今后的专业学习是大有裨益的。
在计算机、互联网和通讯技术的驱动下,大数据与人工智能技术如日中天,应用场景和成果遍及人们的日常生活和各个行业领域。但这些技术的支撑离不开数学、统计学等相关科学理论。
为什么统计学、数据科学与大数据技术专业是大数据与人工智能领域最核心的专业?在这一模块,我们先从直观感觉入手,初步了解”传统的”统计学和”新兴的”数据科学,以拨开专业、专业学习的迷雾,为接下来深入学习做好准备。
4.1 统计学的历史
统计学是一门既古老又崭新的“收集、分类、处理和分析事实和数据的科学”。
说其古老,是因为它已有300年左右的历史,它历经了人类的农业经济时代、工业经济时代,又走进了正在和已经到来的大数据与人工智能时代。说其崭新,因为它虽然已产生了300余年,但至今仍在快速发展。今天,计算机、互联网和通信技术使它拥有更多、更高效的方法和手段,以及更广泛的研究对象、应用领域,以及更广阔的发展前景。
下面的图片概括了统计学的发展,展示了统计学重要的历史节点、人物以及事件,详细见其高清晰度的图片,南安普顿大学网站可以查询到更多的关于概率论和统计学的历史资料,大家可以去了解。

- 统计学的创立时期
统计学的萌芽产生在欧洲。17 世纪中叶至 18 世纪中叶是统计学的创立时期。在这一时期,统计学理论初步形成。并形成了国势学派和政治算术学派两大主要学派。
国势学派产生于 17 世纪的德国,由于该学派主要以文字记述国家的显著事项,故又称记述学派。该学派偏重事物性质的分析与解释,不注重数量计算,为统计学的发展奠定了经济理论基础。
政治算术学派产生于 19 世纪中叶的英国,创始人是威廉 · 配第(1623-1687),其代表作是他于 1676 年完成的《政治算术》一书。这里的“政治”是指政治经济学,“算术”是指统计方法。该学派注重数量对比分析,为统计学的形成和发展奠定了方法论基础。
- 统计学的发展时期
18 世纪末至 19 世纪末是统计学的发展时期。在这时期,形成了两大主要学派,即数理统计学派和社会统计学派。
在 18 世纪,由于概率理论日益成熟,为统计学的发展奠定了基础。19 世纪中叶,把概率论引进统计学而形成数理学派。其奠基人是比利时的阿道夫 · 凯特勒(1796-1874),其主要著作有:《论人类》、《概率论书简》、《社会制度》和《社会物理学》等。其主张是为统计学提供和建立可量化的理论和通用的方法。
社会统计学派产生于 19 世纪后半叶,创始人是德国经济学家、统计学家克尼斯(1821-1889), 主要代表人物主要有恩格尔(1821-1896)、梅尔(1841-1925)等人。他们融合了国势学派与政治算术学派的观点,沿着凯特勒的 “基本统计理论” 向前发展,但在学科性质上认为统计学是一门社会科学,其根本是研究社会现象变动原因和规律性的实质性科学,与数理统计学派通用方法是相对立的。
- 统计学的迅速发展时期
20 世纪初以来,科学技术迅猛发展,社会发生了巨大变化,统计学进入了快速发展时期。归纳起来有以下几个方面。
- 由计数统计向推断统计发展
- 由社会、经济统计向多分支学科发展
- 信息论、控制论、系统论与统计学的相互渗透和结合,使统计科学进一步得到发展和日趋完善
- 计算技术和一系列新技术、新方法在统计领域不断得到开发和应用
- 统计在现代化管理和社会生活中的地位日益重要
- 统计学的现在与未来
在科学技术飞速发展的今天,统计学广泛吸收和融合相关学科的新理论,不断开发应用新技术和新方法,深化和丰富了统计学传统的思维、理论与方法,并不断拓展了新的领域。
作为一个极具预见性的科学家,C.R.Rao 预见了大数据革命以及由数学、统计学和计算机科学所构成的交叉学科。在 2007 年,他建立了 C.R. Rao 数学、统计学和计算机科学前沿研究所(AIMSCS)。他持续拓展统计学的边界来解决大数据时代和人工智能中的挑战问题。
4.2 认识统计学
人们在日常生活和生产实践中,经常遇到”纠结”的问题,“纠结”的 原因往往是由结果的不确定性所引起,“纠结”是广泛存在的,特别是往往又需要在”纠结”中作出”正确”的决定,这样的例子比比皆是!

结果的不确定性不仅存在于人们的日常生活中,在大自然和人类社会生产实践活动中,更是广泛地存在。人们不仅想知道到底哪一个结果会出现,更想了解其出现与否的规律性。
如下一系列问题:
在新冠疫情肆虐的当下,政府部门根据疫情防控的需要,会进行局部全民核酸检测。从新闻中得知,几十万、几百万甚至逾千万人的检测,很短时间就会出结果,为疫情防控赢得了报告的时间,这是怎么做到的呢?
一销售商, 在过去的两个月中,通过电视广告促销某种产品,如何分析两个月的电视广告效果与接下来一个月的销售量之间是否存在相关关系?
如何分析、评价生活习惯(如吸烟、饮酒、高盐饮食之类) 对健康的影响, 以及环境污染对健康的影响?
银行决定从明年初降低储蓄存款利率。 如何分析降低利率前后, 居民储蓄热情下降的规律?
总统的支持率为 58% 是如何计算出来的?
明天是否会下雨?
一个人的收入与哪些因素有关, 主要因素是什么?
在生产过程中, 由于原材料、设备调整及工艺参数等条件可能的变化,而造成生产条件不稳定;如何在生产过程中随时监测, 以便及时加以调整, 避免大量出废品。
大批量的产品生产出来后, 如何检验其质量是否达到要求, 是否可以出厂?
某人胃部不适, 如何根据该人的有关临床诊断数据, 对病人胃部是否产生病变作出诊断?
在生物学和医学上, 人体变异是一个重要的因素,不同的人的情况千差万别,其对一种药物和治疗方法的反应也各不相 同, 如何对一种药物的疗效或治疗方法进行评价?
某个湖里面有多少条鱼?
在农业上, 如何通过选种、选择耕作条件以及肥料选择等, 提高农作物的产量与质量?
股票价格的涨跌与哪些因素有关? 如何估计证券、期货市场行情规律?
服装的标准 (尺码) 是怎样制定的?
在一定条件下,上述问题都是没有标准的、确定性的答案,换句话说,即使条件相同,结果依然存在着某种程度的不确定性。
要从根本上说清楚统计学,无法绕开概率论与数理统计两个数学分支。
我们知道,微积分是研究连续量的数学,线性代数是研究离散量的数学,那么有没有专门研究不确定性的数学呢?有的,概率论就是专门研究随机量的数学!
然而,在利用概率论分析和研究随机性或不确定性的过程中,往往需要一些反映随机性或不确定性的”依据”,这些”依据”往往表现为人们通常所称的数据。按照概率论的原理和理论,对问题涉及的数据进行分析的理论和技术,就是我们所说的数学的一个分支,称为数理统计!
至此,概率论是基于随机变量研究不确定性或随机性的数学,数理统计是基于样本数据研究不确定性或随机性的数学。常说的统计学则是以概率论与数理统计为核心理论基础的一门收集、整理、分析、洞见和解释数据的科学。
现代统计学家C.R.Rao对统计学做了颇有哲学味道的概括,精辟地诠释了统计学的意义所在:
因此,统计学强调搜集、整理、分析、描述、解释隐藏在数据中的不确定性的规律性,其应用几乎覆盖了社会科学和自然科学的各个领域,从以下统计学的应用即可略见一斑。
| 统计调查分析学 | 核算统计学 | 监督统计学 | 管理统计学 |
| 描述统计学 | 推断统计学 | 经济统计学 | 宏观经济统计学 |
| 微观经济统计学 | 社会统计学 | 教育统计学 | 文化与体育统计学 |
| 卫生统计学 | 司法统计学 | 社会福利与保障统计学 | 生活质量统计学 |
| 人口统计学 | 环境与生态统计学 | 自然资源统计学 | 环境统计学 |
| 国际标准分类统计学 | 化学统计 | 国际比较统计学 | 农业科学 |
| 生物统计学 | 生物统计学 | 商务统计学 | 商用统计学 |
| 工程统计学 | 文献统计学 | 心理统计学 | 统计物理学 |
| 化学统计学 | 统计语言学 | 档案统计学 | 心理统计学 |
| 水文统计学 | 运动统计学 | …… |
从统计学诞生、发展的历史看,由于受当初客观条件的制约,数据的获取及存贮有很大的局限性,或者说统计学诞生于”数据稀缺时代”;因此,统计学的核心特征是样本推断总体,其核心理论是基于样本数据的统计推断,即使用所获取的少量代表性很强的样本数据;现在通常把基于样本数据的统计学归于传统统计学范畴。
传统统计学在经济社会中,依然起着重要和不可或缺的作用;“甚至大多数所谓大数据问题,归根结底依然是样本统计的范畴”!
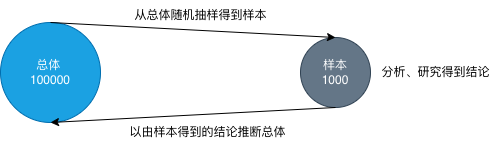
图 4.1: 传统统计学
时至今日,计算机、互联网和通讯技术的快速发展,使得类型各异的海量数据、实时数据非常易于获取和存贮,可用于处理和分析的数据很自然地不再局限于”精挑细选”的样本数据,统计学的研究与应用不断打开新的视角,其研究范围和研究方法也在不断地更新,诞生了数据挖掘、统计学习等有别于传统统计学的技术,开启了现代统计学的时代。

图 4.2: 现代统计学
最后我们指出,统计学家在数据科学的发展过程中做出了,并正在做出重要的、突出的贡献。例如,2001 年第一篇以数据科学为标题的学术论文:“Data Science:an action plan for expanding the technical areas of the field of statistics”(International statistics review 2001),就是由统计学家 Cleveland W S发表,并引起学术界和工程界的高度关注。
4.3 数据科学的由来
面对类型各异的海量数据和各行各业旺盛的基于数据的需求,数据处理与分析理论与技术不断被挑战,人们需要新的智慧、新的思维、新的技术和新的工具,满足大数据与人工智能时代需要,以跨学科和知识重构为鲜明特色的科学——数据科学应运而生,数据科学的理论、方法、技术,本质上依然是统计学的延伸和拓广,并在近十年得到了快速的发展。
下面以年代事件为背景,大致将数据科学的发展过程分为两个阶段,从时间上看,2012年基本公认为是一个转折点。
萌芽阶段
- 1974年,著名计算机科学家、图灵头获得者 Peter Naur 的专著”Concise Survesy of Compueer Methods”中首次明确提出”数据科学 (Data Science)“的概念,术语“数据科学”首次出现在学术专著中。
- 2001年,当时在贝尔实验室工作的 William S. Cleveland 在期刊International Statistical Reviered 发表了题为“Data Science: an Action Plan for Expanding the Technical Areas of the Field of Statistics”的论文,术语“数据科学”首次出现在学术论文的标题中,并被权威论文专题探讨。
- 2003年,国际科学理事会(the International Council for Science, ICSU) 的 CODATA (the Committee on Data for Science and Technology) 发行第一本以“数据科学”命名的学术期刊—数据科学学报(The Data Science Journal) 。
- 2009年,Troy Sadkowsky 等在Linkedln 上组建了第一个数据科学家群— The Data Scientists Group.
- 2010年,Drew Conway 提出了第一个揭示数据科学理论基础的维恩图 — The Data Science Venn Diagram.
- 2011年,DJ Patil 出版了专著”Building Data Science Teams”“,系统讨论了数据科学家的能力要求及如何组建数据科学家团队问题。
快速发展阶段
- 2012年,数据科学中的相关思想成功地应用于奥巴马团队的总统竞选工作,受到社会各界的广泛关注;Davenport T H和D J Patil 在《哈佛商业评论(HarvardBusiness Review)»上发表了题目为“Data Scientist: The Sexiest Job of the 21st Century”的论文;Schutt R 在哥伦比亚大学开设第一门数据科学课程”数据科学导论”Introduction to Data Science”。
- 2013年,Mattmann C A 在Nature杂志上发表题目为“计算:Computing: A Vision for Data Science”的论文;Dhar V 在《美国计算机学会通讯 (Communications of the ACM) 》上发表题目为“Data Science and Prediction”的学术论文;Provost F 和Fawcett出版了专著”Data Science for Business”; Mayer- Schonberger V 和 Cukier K 出 版了专著”Big data: A Revolution That Will Transform How We Live, Work,and Think”; Schutt R 和O’Neil c 出版专著”Doing Data Science”。
- 2014年,Zumel N, Mount J,Porzak J 等出版了专著”Practical Data Science with R”,较系统地介绍了如何运用R 开展数据科学工作。
- 2015年,美国白宫任命 D J Patil 为首席数据科学家;Lillian Pierson 出版专著”Data Science for Dumamies”; Monya Baker 在Nature杂志上发表论文“Data Science: Industry Allure”
时至今日,数据科学研究与应用仍在持续、深入和快速发展中。
4.4 初识数据科学
如今人们所说的“大数据”主要指的是在云计算、物联网、互联网、传感器以及大型科学和观测仪器等新技术环境下产生的具有体量大、变化快、类型多、价值分散等新特征的“新数据”的统称。
——Eric·Brynjolfsson ——Economist, Director of electronic commerce center, MIT
这也就意味着,亟待升级和更新我们的“知识”结构。截止到目前,关于数据科学没有标准的、严格的定义,但数据科学是数学、统计学和计算机学科的交叉,得到了普遍的认同; 2010年,Drew Conway用一张Venn图表示数据科学的知识结构,并为人们所认可和推崇。
关于数据科学,比较流行的描述:
数据科学是科学发现和实践的结合,其包括对大量类型各异的数据进行收集、管理、清洗、分析、可视化和结果解释,其应用遍及各种科学和交叉领域。
数据科学是一个跨数学、统计学、计算机科学、应用行业等多学科领域的,从数据中获取知识的科学方法,技术和系统集合,其目标是从数据中提取出有价值的信息,它结合了诸多领域中的理论和技术,包括应用数学、统计、模式识别、机器学习、人工智能、数据可视化、数据挖掘、数据仓库,以及高性能计算等。
而对于在企业从事数据相关工作的顶级岗位,习惯上称为数据科学家。
数据科学家是指综合使用一整套科学工具、技术(数学、统计、计算、视觉、分析、试验、艺术、问题界定、模型建立与检验等)和智慧,能从数据中获得新发现、最大限度洞见数据的价值的,懂系统架构、精数据分析、会领域知识的,熟悉第四范式的新型人才。

总而言之,数据科学内涵可以概括为三个方面:
- 一方面是研究数据本身,研究数据的各种类型、状态、属性及变化形式和变化规律;
- 另一方面是为自然科学和社会科学研究提供一种新的方法,称为科学研究的数据方法,其目的在于揭示自然界和人类行为现象和规律;
- 具有鲜明的综合性、跨学科的特色。
借助现代计算机技术和算法,数据科学从数据集中:
- 发现隐藏的趋势
- 充分利用发现的趋势做预测
- 计算每种结果出现的概率
- 快速判断哪个结果是最优的
而研究这些问题通常要经历以下 4 个主要步骤:
- 首先,必须处理和准备待分析的数据
- 其次,根据研究需求挑选合适的算法
- 再次,对算法的参数进行调优,以便优化结果
- 最后,创建模型,并比较各个模型,从中选出最好的一个
4.5 数据科学数学、统计学知识架构
这张图抛开其应用场景和领域,粗略概括了数据科学、统计学的知识框架,这将有助于帮助同学们在大脑中建立一张大比例尺的全貌图,帮助同学们在专业学习过程中思考和把握。

图 4.3: 数据科学知识架构
数据科学始终关注科学(而非仅仅是数据本身),数据分析师或数据科学家在在研究和探索过程中,通常具有如下的一些特点:
- 通过探测潜在的动态来建模过程
- 提出和构建假设
- 严格评估数据源的质量
- 量化数据和预测的不确定性
- 培养个人从信息流中识别隐藏模式的感觉
- 清楚地了解模型的局限性
- 理解数学证明及其背后的所有抽象逻辑
然而,数据科学并不依赖于特定的学科领域,却可以在具体项目中处理各种看似极具专业性的问题,如癌症诊断和社会行为分析等,这会转变为各种令人眼花缭乱的\(n\)维数学对象、概率、统计分布、优化目标函数等数学或统计问题,这也正是称其为数据科学的缘由。
4.6 数据科学与统计学的关系
前面我们分别介绍了统计学和数据科学,那么,对数据分析稍稍了解一点的人,都会不约而同地思考一个问题:统计学和数据科学有何异同?
截止目前,人们都在思考,试图比较专业和全面地做出回答,以下这张图,是得到了普遍公认的,用 wenn 图表达了数据科学的内涵和外延。

图 4.4: 统计学与数据科学
接下来这张图来自张宏图教授,从人的角度,刻划了统计学家和数据科学家的前世今生,值得思考。

图 4.5: 统计学家与数据科学家
最后,你什么时候需要统计学,什么时候需要数据科学呢? Google 首席决策师,统计学家Cassie Kozyrkov,从解决实际问题的角度,给出了这张决策图。


图 4.6: 统计学家与数据科学家的思维
